Method
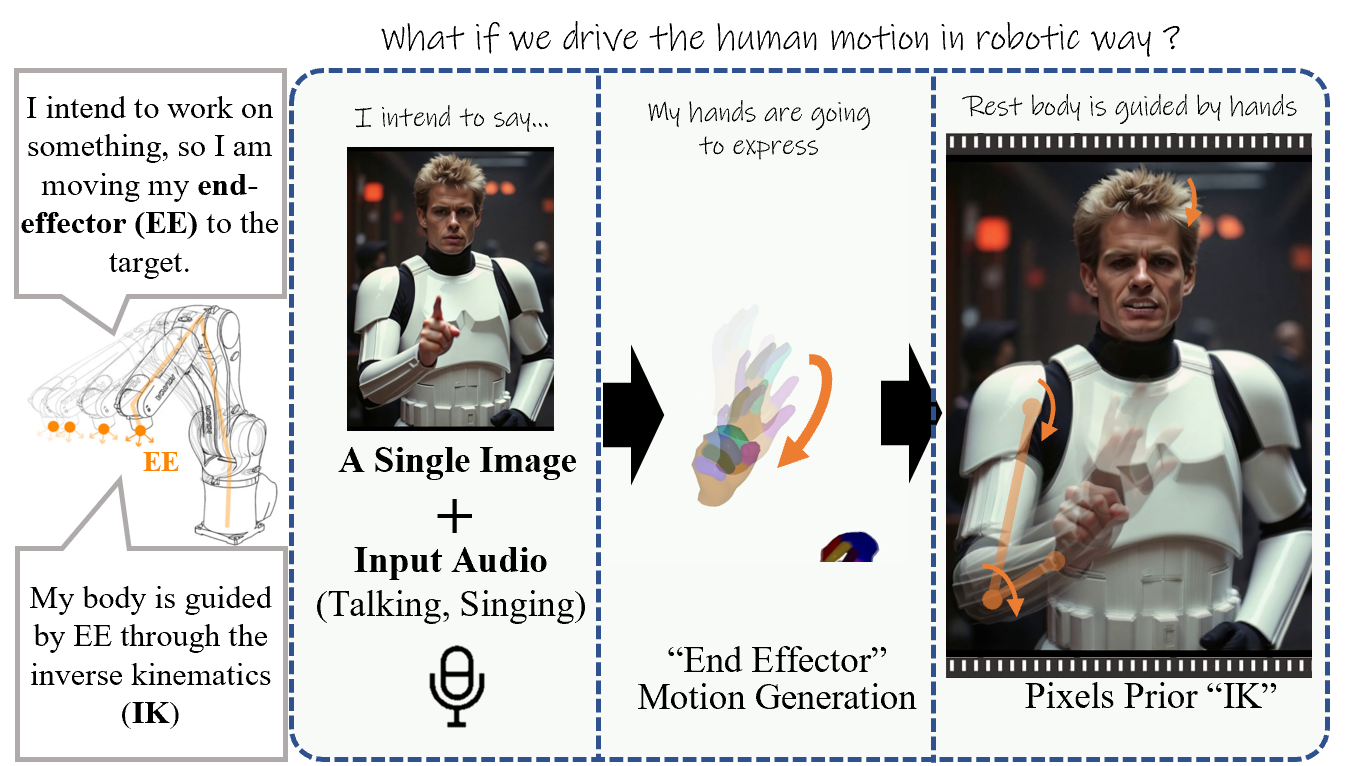
End-Effector Guided Approach
The motivation behind our method. Human motion, similar to that of robots, involves planning the "end-effector" (EE), typically the hands, towards the target situation. The rest of the body then cooperates accordingly with the EE, using inverse kinematics principles.
Stage 1: Audio to Hand Poses
Generate hand poses directly from audio input, leveraging stronger correlation between audio signals and hand movements.
Stage 2: Diffusion Synthesis
Employ diffusion model to synthesize video frames with realistic facial expressions and body movements.