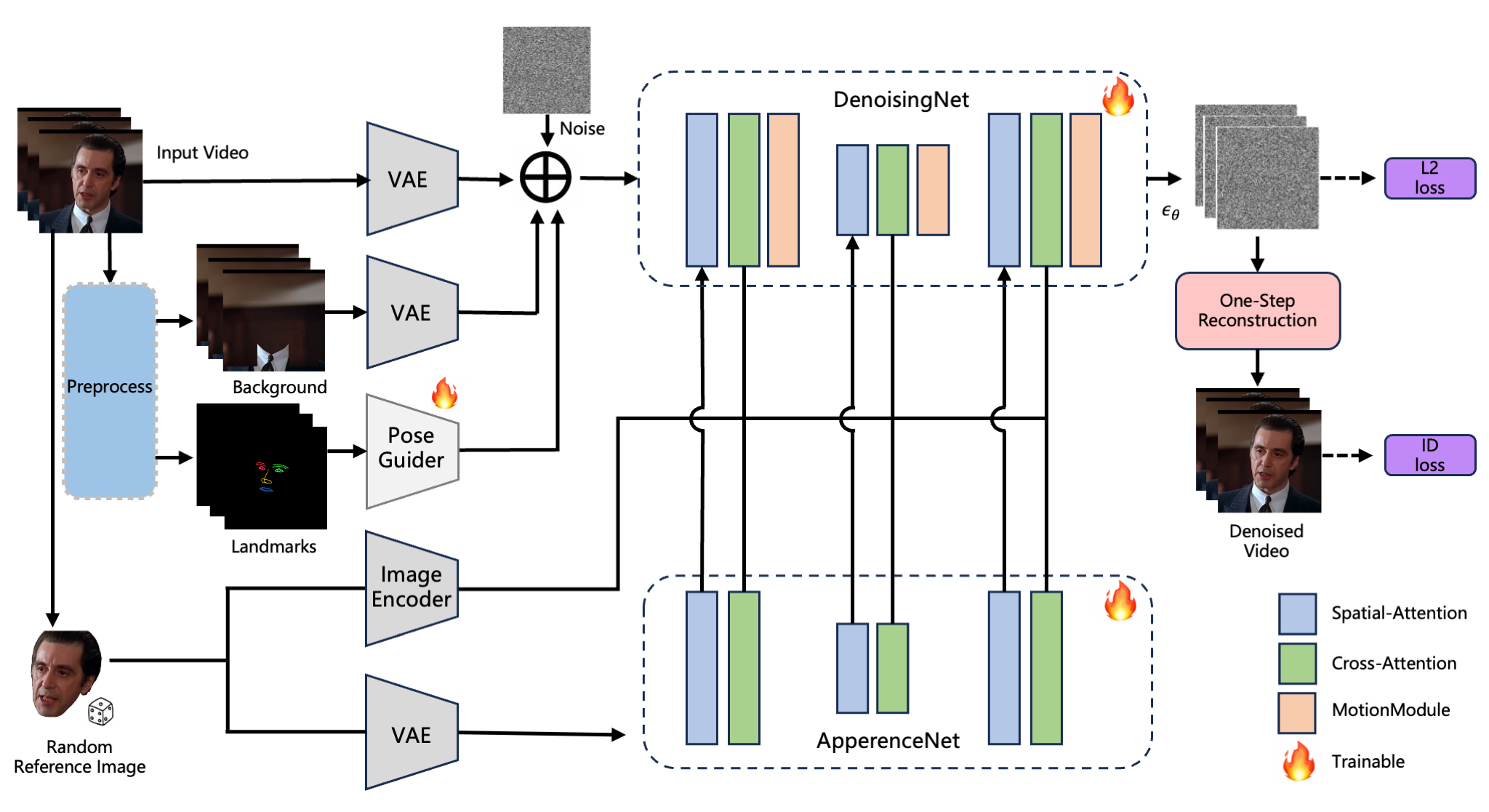
Overview

Revolutionary Head Swapping Technology
Illustration of Video Head Swapping. Given a reference image and video sequence as input, our model can generate high-fidelity head swapping results that accommodate diverse hairstyles, expressions, and identities.
One-Shot Swapping
Seamless head transplantation from single reference image
Expression Control
Controllable facial expressions and movements
High Fidelity
Preserve identity and background seamlessly