Wan-S2V
Wan-S2V
正在加载内容...
Wan-S2V
Transform static images and audio into high-quality, cinematic videos with AI
Wan-S2V is an AI video generation model that transforms static images and audio into high-quality videos. Our model excels in film and television application scenarios, capable of presenting realistic visual effects, including generating natural facial expressions, body movements, and professional camera work. It supports both full-body and half-body character generation, and can high-quality complete various professional-level content creation needs such as dialogue, singing, and performance.
Wan-S2V takes a single image and audio input to generate high-quality, synchronized video content
Prompt: "In the video, a man is walking beside the railway tracks, singing and expressing his emotions while walking. A train slowly passes by beside him."
Prompt: "In the video, a woman is talking to the man in front of her. She looks sad, thoughtful and about to cry."
Prompt: "In the video, a woman is singing. Her expression is very lyrical and intoxicated with music."
Prompt: "The video shows a woman with long hair playing the piano at the seaside. The woman has a long head of silver white hair, and a flame crown is burning on her head. The girls are singing with deep feelings, and their facial expressions are rich. The woman sat sideways in front of the piano, playing attentively."
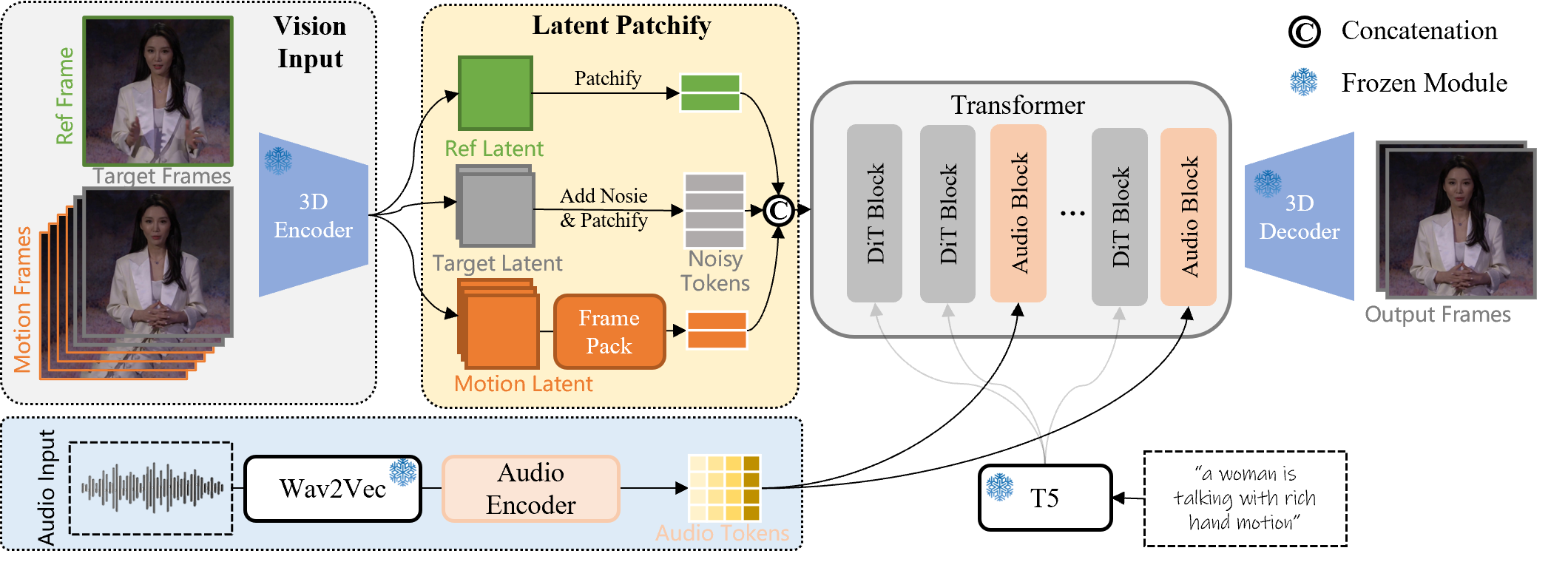
Overview of our pipeline
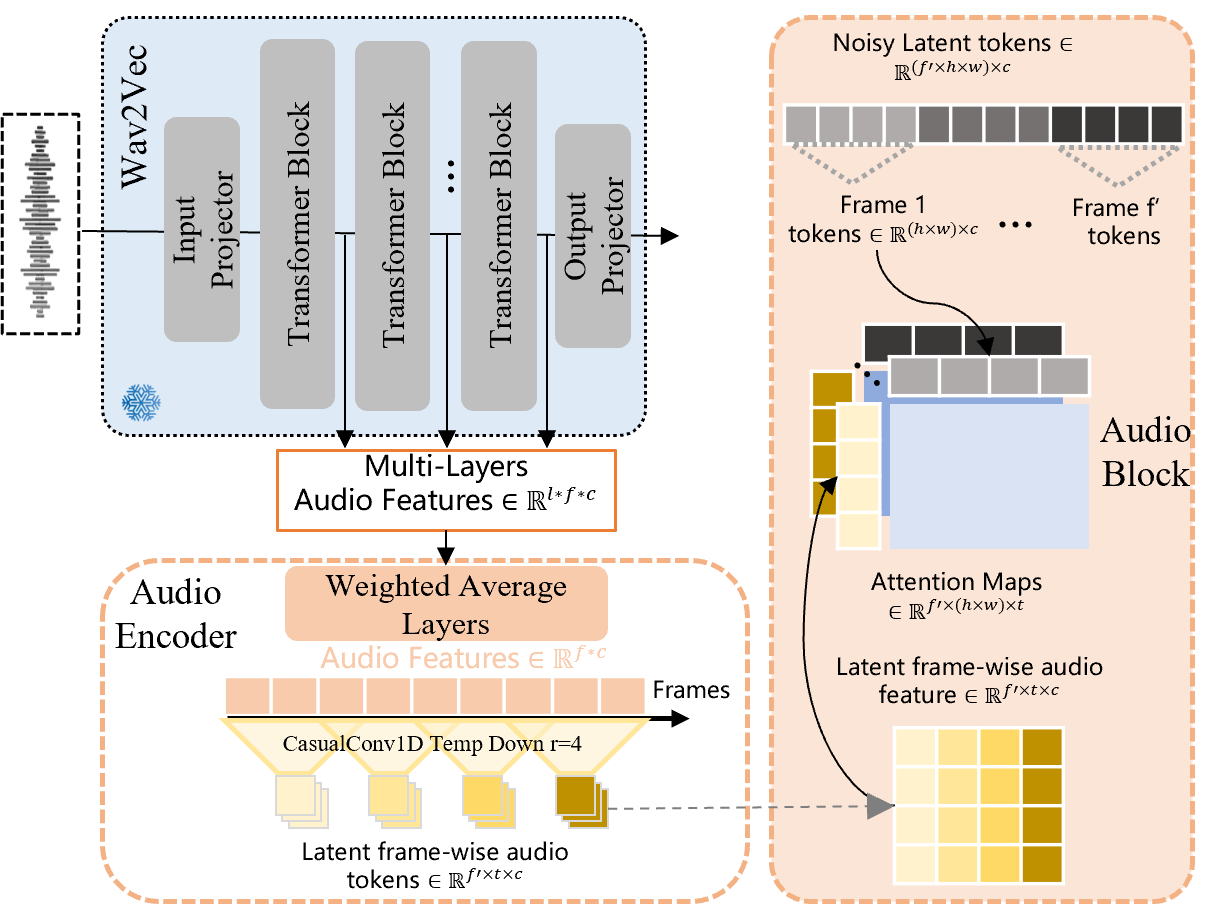
The pipeline of the audio injection
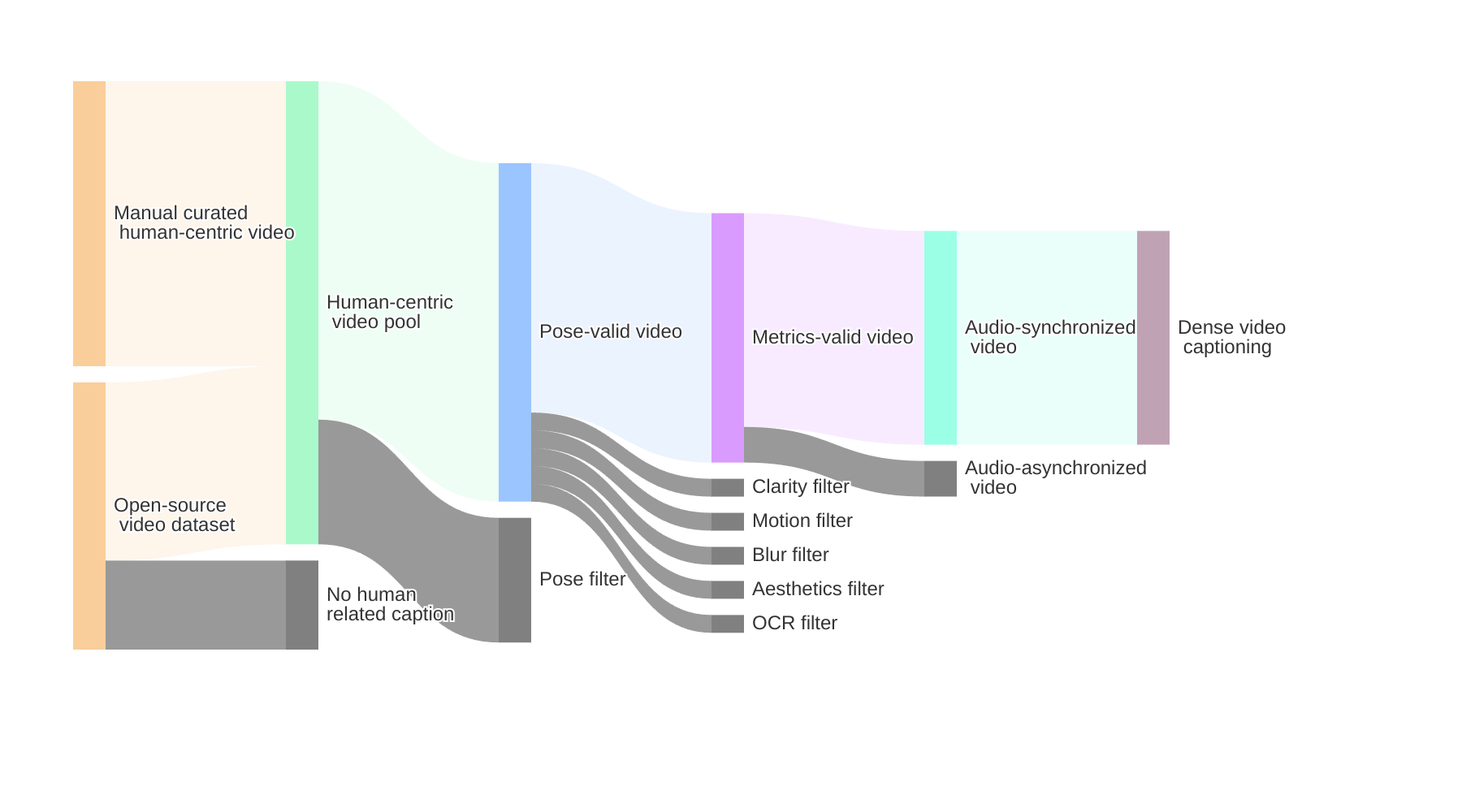
Our data collection strategy combines automated screening of large-scale datasets (OpenHumanVid, Koala36M) with manual curation of high-quality samples. We focus on videos featuring human characters engaged in specific activities like speaking, singing, and dancing, creating a comprehensive dataset of millions of human-centric video samples.
Prompt: "In the video, a woman stood on the deck of a sailing boat and sang loudly. The background was the choppy sea and the thundering sky. It was raining heavily in the sky, the ship swayed, the camera swayed, and the waves splashed everywhere, creating a heroic atmosphere. The woman has long dark hair, part of which is wet by rain. Her expression is serious and firm, her eyes are sharp, and she seems to be staring at the distance or thinking."
Prompt: "In the video, a boy is sitting on a running train. His eyes are blurred. He is singing softly and tapping the beat with his hands. It may be a scene from an MV movie. The train was moving, and the view passed quickly."
Prompt: "In the video, there is a man's selfie perspective. He glides in the sky in a parachute. He sings happily and looks engaged. The scenery passes around him."
Our method is capable of generating film-quality videos, enabling the synthesis of film dialogues and the recreation of narrative scenes.
Prompt: "The video shows a group of nuns singing hymns in the church. The sky emits fluctuating golden light and golden powder falls from the sky. Dressed in traditional black robes and white headscarves, they are neatly arranged in a row with their hands folded in front of their chests. Their expressions are solemn and pious, as if they are conducting some kind of religious ceremony or prayer. The nuns' eyes looked up, showing great concentration and awe, as if they were talking to the gods."
Prompt: "In the video, a man is lying on the sofa with his hands folded on his legs. He is talking with his legs cocked. The lamp flickered. The camera slowly circled, as if it were a movie scene."
Prompt: "In the video, a man in a suit is sitting on the sofa. He leans forward and seems to want to dissuade the opposite person. He speaks to the opposite person with a serious expression of concern."
Our model can generate character actions and environmental factors in videos according to instructions, thereby creating video content that better fits the theme.
Prompt: "In the video, it is raining heavily. It shows a man who is topless and has clear muscle lines, showing good physical fitness and strength. The rain wet his whole body. His arms were open and he was singing happily. His expression was engaged and his hands were slowly extended. The man's head is slightly raised, his eyes are upward, and his mouth is slightly open. His expression was full of surprise and expectation, giving a feeling that something important was about to happen."
Prompt: "In the video, a man is holding an apple and talking, he takes a bite of the apple."
We conduct comprehensive quantitative comparisons with state-of-the-art methods across multiple evaluation metrics.
| Method | FID↓ | FVD↓ | SSIM↑ | PSNR↑ | Sync-C↑ | EFID↓ | HKC↑ | HKV↑ | CSIM↑ |
|---|---|---|---|---|---|---|---|---|---|
| EchoMimicV2 | 33.42 | 217.71 | 0.662 | 18.17 | 4.44 | 1.052 | 0.425 | 0.150 | 0.519 |
| MimicMotion | 25.38 | 248.95 | 0.585 | 17.15 | 2.68 | 0.617 | 0.356 | 0.169 | 0.608 |
| EMO2 | 27.28 | 129.41 | 0.662 | 17.75 | 4.58 | 0.218 | 0.553 | 0.198 | 0.650 |
| FantasyTalking | 22.60 | 178.12 | 0.703 | 19.63 | 3.00 | 0.366 | 0.281 | 0.087 | 0.626 |
| Hunyuan-Avatar | 18.07 | 145.77 | 0.670 | 18.16 | 4.71 | 0.7082 | 0.379 | 0.145 | 0.583 |
| Wan2.2-S2V-14B | 15.66 | 129.57 | 0.734 | 20.49 | 4.51 | 0.283 | 0.435 | 0.142 | 0.677 |
Table 1: According to actual measurement data, Wan2.2-S2V achieved the best or near-best performance among similar models in core metrics such as FID (video quality), EFID (expression authenticity), and CSIM (identity consistency).